Внутренний мир memcached

Многие знают что такое memcache и используют его в своих проектах. Но мало кто знает как он работает. Будут затронуты следующие особенности:
- Big-O
- LRU
- Memory allocation
Big-O
Большинство функций memcache (например, add, get, set, flush…) являются статическими по времени. Не важно сколько элементов в кэше, метод будет выполнятся столько времени, сколько бы он выполнялся если бы внутри кэша был только один элемент. Использование такого подхода имеет свои преимущества (memcache остается быстрым) и недостатки — например, вы не можете перебрать все элементы в кэше. Для того, что бы это выполнить вам необходимо использовать некую функцию O(N), которая зависит от количества элементов. То есть, количество времени затраченного на данную операцию возрастет вдвое, если удвоить количество элементов кэша. Именно по этой причине memcache не поддерживает функциональность такого рода.
LRU алгоритм
Перед запуском memcached вы должны указать сколько памяти он будет использовать. ОС выделит необходимый объем памяти сразу после запуска, например, если вы хотите использовать 1GB памяти для хранилища, то ОС выделит 1GB только для memcached и эта память не сможет быть использована другими приложениями (apache, php…) Но из-за того, что мы ограничиваем количество памяти используемое приложением, рано или поздно наступит момент, когда все данные просто не будут помещаться в память. Что же делать в таком случае?
Как вы догадались — memcahce будет удалять старые данные, что бы освободить место для новых. Но ему нужно знать какие же объекты можно удалить. Можно удалить наибольший объект, таким образом мы сразу получим много места. Или можно удалять элементы по порядку их добавления в кэш и получить FIFO (First In, First Out) схему кэширования. Но, memcached использует гораздо более продвинутый метод, называемый LRU: Least Recently Used (наименее часто используемый). Иными словами, он вытесняет из памяти элементы которые не использовались наибольшее количество времени. А это не обязательно наибольший или первый сохраненный элемент.
Внутри все объекты имеют «счетчик». Этот счетчик хранит timestamp. Каждый раз, когда объект создается или запрашивается, в счетчик помещается текущее время. И как только memcached нужно вытеснить какой-то объект — он ищет объект с наименьшим показателем счетчика. Это может оказаться объект который вообще не запрашивался или который не запрашивался наибольший промежуток времени.
В результате получается простая система с очень эффективным использованием кэша.
Memory allocation
В прошлой статье была затронута эта тема. Вкратце все происходит таким образом: при запуске приложения с помощью метода malloc() ОС выделяет для приложения необходимый объем памяти, который демон заполняет по своему усмотрению. Для избежания фрагментации в memcached используется свой метод для хранения данных — Slab и Chunk.
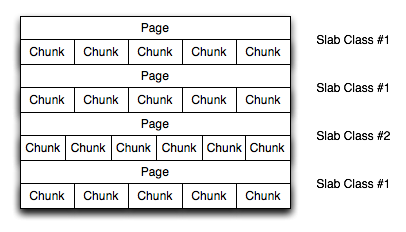
Вся выделяемая память разбивается на блоки фиксированного размена (Slab), которые содержат в себе другие под-блоки (Chunk). Каждый Slab содержит в себе 1МБ / (Chunk size) Chunk’oв. По умолчанию, размер Chunk’ов начинается с 96 байт и дальше увеличивается с коэффициентом 1.25. Например, следующий размер будет 120 байт, далее — 152, 192…. и так до размера в 1МБ (размера всего Slab’а). Убедится в этом вы можете выполнив команду «memcached -vv -u nobody»:
slab class 1: chunk size 96 perslab 10922slab class 2: chunk size 120 perslab 8738slab class 3: chunk size 152 perslab 6898slab class 4: chunk size 192 perslab 5461slab class 5: chunk size 240 perslab 4369slab class 6: chunk size 304 perslab 3449…
Каждый Chunk в себе несет 48 байт которые используются для хранения ключей и флагов. То есть, Chunk размером 96 байт, будет содержать в себе максимум 48 байт пользовательских данных, 120 байт — 72 байта, и т.д. Это значение можно изменить, просто запустив memcache с параметром -n и указав количество байт выделяемое для ключей, флагов. Например, выполнив «memcached -vv -unobody -n 8″ получим:
slab class 1: chunk size 56 perslab 18724slab class 2: chunk size 72 perslab 14563slab class 3: chunk size 96 perslab 10922slab class 4: chunk size 120 perslab 8738slab class 5: chunk size 152 perslab 6898slab class 6: chunk size 192 perslab 5461….
После запуска, memcached инициирует создание по одной копии каждого класса Chunk’ов. Дальнейшее создание Slab’ов происходит только по требованию.
При помещении данных в кэш, демон будет выделять Slab со Chunk’ами наиболее подходящего размера. Для данных размеров в 96 байт будет выделен Chunk соответствующего размера, а для 100 байт будет выделена ячейка размером в 120 байт. Как видно мы получаем 20 байт не используемой памяти. Это не страшно, когда размер данных стремится к верхней границе, но что же делать если наоборот? В таком случае вы можете изменить коэффициент роста размера Slab во время запуска приложения с помощью опции -f. Например, при запуске такой командой «memcached -vv -unobody -f 2″ мы получим 14 классов Slab’ов, размер Chunk’ов в которых увеличивается в двое:
slab class 1: chunk size 96 perslab 10922slab class 2: chunk size 192 perslab 5461slab class 3: chunk size 384 perslab 2730slab class 4: chunk size 768 perslab 1365slab class 5: chunk size 1536 perslab 682slab class 6: chunk size 3072 perslab 341slab class 7: chunk size 6144 perslab 170slab class 8: chunk size 12288 perslab 85slab class 9: chunk size 24576 perslab 42slab class 10: chunk size 49152 perslab 21slab class 11: chunk size 98304 perslab 10slab class 12: chunk size 196608 perslab 5slab class 13: chunk size 393216 perslab 2slab class 14: chunk size 1048576 perslab 1
Благодаря этой небольшой и нехитрой оптимизации мы можем более рационально использовать выделенную память.
Итог
Порой полезно более глубоко взглянуть на некоторые системы, которые мы принимаем как само собой разумеющиеся. Как и в реальной жизни в них все гораздо сложнее чем кажется с первого взгляда и они состоят из множества методов которые решают разные задачи. Знание и понимание которых может помочь Вам и в Вашем деле.